

Written by Julie Bick, Ph.D.
In the fast-paced realm of healthcare, innovation is constantly reshaping the landscape of medical research and translational drug development. One of the most transformative trends in recent years is the integration of so called ‘big data’ into healthcare and clinical trials. This shift is not just a technological leap; it represents a paradigm change in the way we conduct research and make medical advancements. In this blog, we will explore what big data means, and how drug development is transitioning to big data-driven clinical trials and the profound impact this is having on the future of healthcare.
Traditional clinical trials have long been the gold standard for evaluating the safety and efficacy of new treatments. These trials typically involve carefully controlled studies with a select group of participants, often lasting for years. While this approach has led to numerous breakthroughs, it comes with its own set of challenges, and is plagued by high costs, slow patient recruitment, and a limited diversity in participant pools. Enter Big Data into the arena of drug development. Big data is a term used for the compiling of large and complex data sets, that require database management tools to collate and mine for specific endpoints (Margolis et. al. 2014). It has emerged as a game-changer in various industries, and drug development is no exception. Within the auspices of healthcare, big data refers to the use of large and complex datasets to analyze patient information, genetics, lifestyle factors, biomarkers and more. This wealth of information allows researchers to identify non-intuitive patterns, more accurately assess risks and outcomes, and ultimately to help personalize treatments.
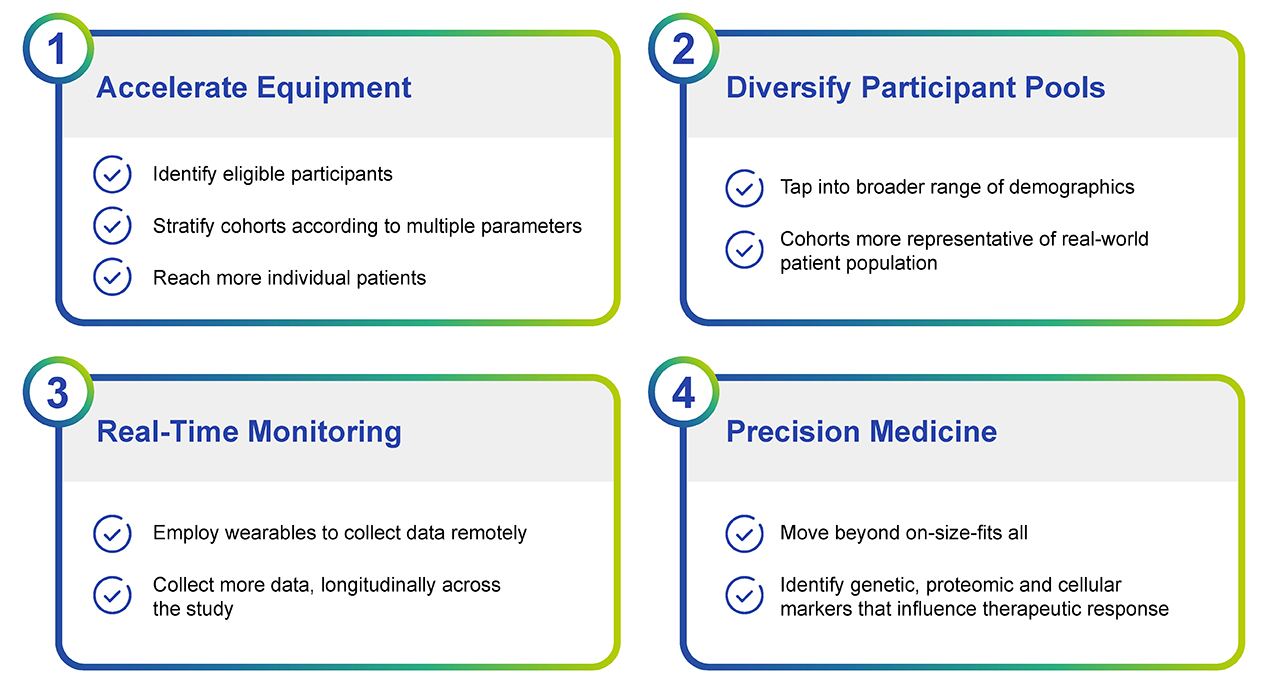
Fig. 1. The incorporation of Big Data into clinical trials is having a profound impact at multiple levels. The hope is that this streamlining will expedite the approval of new drugs and help reduce the rising costs of clinical trials.
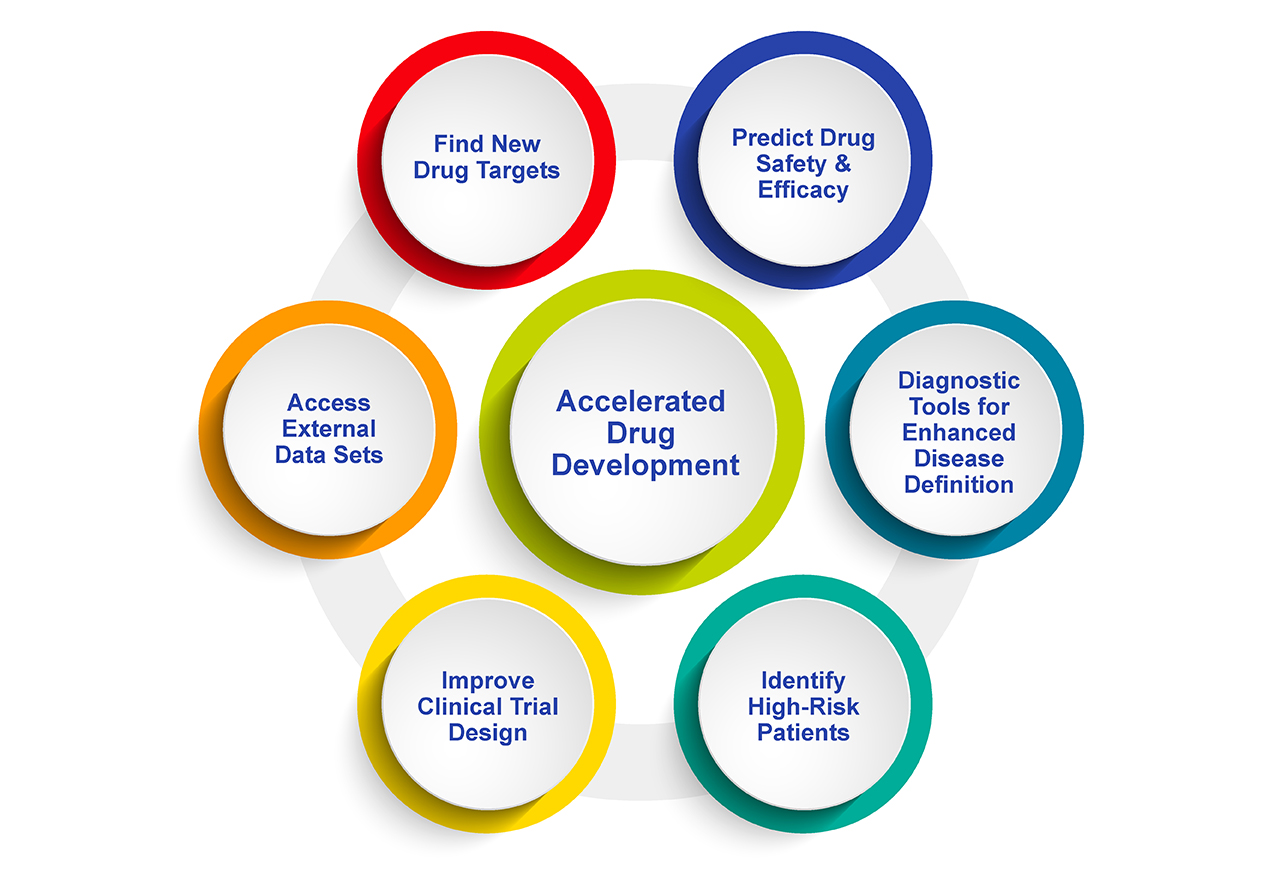
Fig. 2. The Scope of Big Data Analytics in Drug Development, Clinical Trials and Personalized Medicine spans many functions. There is no doubt that big data analytics will improve many facets of drug development, and safety and efficacy evaluation. All of this works to make precision medicine more achievable, to support better patient care.
Traditional randomized clinical trials typically have strict inclusion and exclusion criteria that are used to balance treated versus control arms of the study. However, the biological efficacy of a drug under these conditions, may not reflect real world scenarios, and there is little leeway in the protocols relative to timing, dosing and sequence of drug administration along with comorbidities can complicate conclusions (Nallamothu et. al. 2008). Under the big data model of clinical trials, many of these limitations can be managed and therefore the outcomes more closely resemble real-world features (Albert et. al. 2013).
One of the most impactful drawbacks of traditional trials is the ‘control group’. Depending on the type of trial and the study protocol, the control group may receive no treatment, a placebo, or receive the current standard of care. This is a significant problem for clinical trial recruitment since typically no one wants to be in the control arm; as a result, globally 90% of clinical trials don’t recruit enough patients within their target timelines. The hope of big data is to help alleviate this barrier and mine data from a patient’s past to essentially create these control groups. This would enable researchers to establish rapid preliminary trials to evaluate if a treatment is even worth pursuing before the investment into a full phase I or II clinical trial (See Fig 3). Essentially, the control arm for a trial would be built by mining databases of past clinical trials or electronic medical records (EMRs) to identify subjects who are matched controls for patients in the treatment group. This so called ‘external’ control arm reduces the cost of trials and enables smaller trials to be performed, more expeditiously and with the same scrutiny of traditional trials. The FDA is evaluating this model closely, and for now at least a hybrid model in which the external control arm is supplemented with ‘external controls’ rather than completely replaced is under consideration and with great success to date.
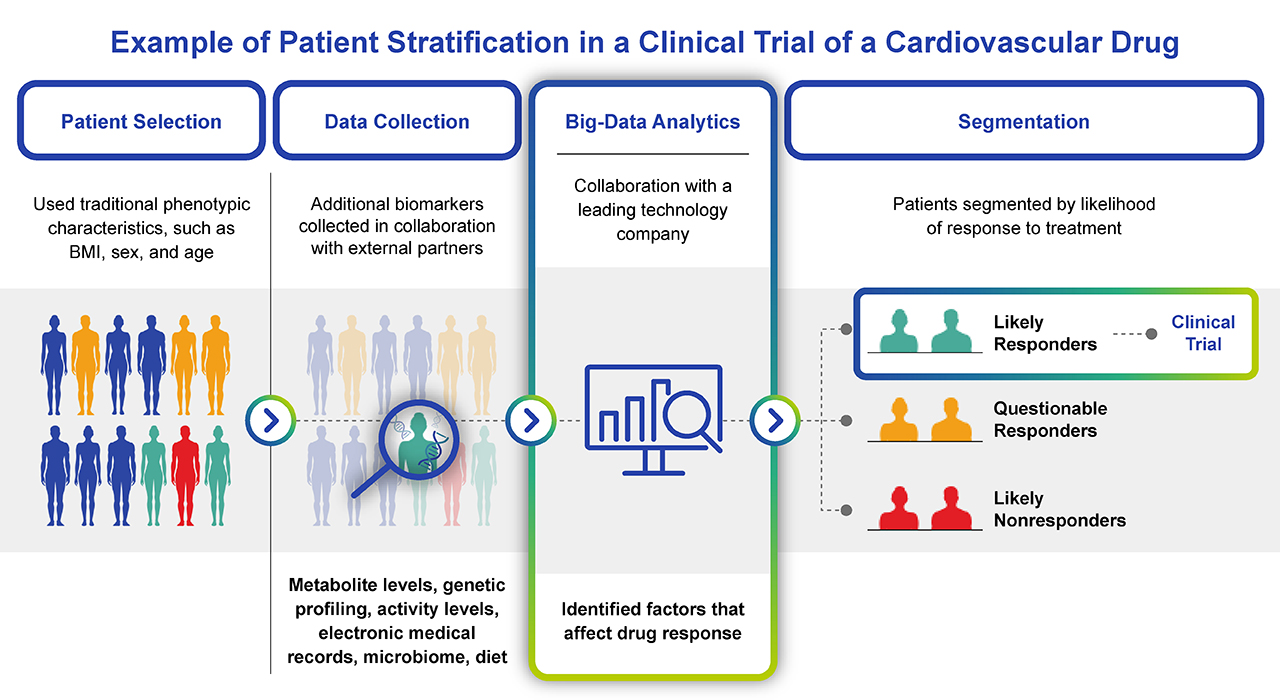
Fig. 3. Example of how big data can streamline the design and recruitment of a clinical trial. Big data analytics goes beyond traditional patient profiling, to assess a multitude of biomarkers and stratify patients before enrolling clinical trial participants. Not only does this help with patient enrollment, but it manages the risks of adverse drug events and non-responders within the trial.
Big data can mean different things based on the context of its acquisition and use. Within hospital settings, EMRs are now commonplace. These records include demographic information, diagnostic and therapeutic information, as well as longitudinal reporting of laboratory test results and physiological monitoring data. In addition to EMRs, most hospitals compile administrative data sets that include hospital discharge reporting that is provided to government agencies and the Healthcare Cost and Utilization Project (HCUP). Unlike most EMRs, administrative datasets can be accessed publicly and used by drug companies for building health related data sets.
Claims data captures the insurance claims between healthcare institutions and the patients they treat for inpatient-, outpatient-, pharmacy and for enrollment. Some insurance companies, along with Medicare and Medicaid provide this type of data to external entities such as drug companies for data mining and for the assessment of unmet medical needs. In a similar vein, population health is now frequently monitored through national surveys, typically around chronic conditions, and the data used to justify the foundational research in specific areas of medicine and support drug development. These surveys may be used to track the prevalence of diseases within the population, or amongst different demographics. Examples include the Medicare Current Beneficiary Survey (http://www.cms.gov/Research-Statistics-Data-and-Systems/Research/MCBS/index.html ); the National Health and Nutrition Examination Survey (http://www.cdc.gov/nchs/nhanes.htm ); the National Medical Expenditure Survey (http://meps.ahrq.gov/mepsweb/ ); the National Health and Aging Trends Study (http://www.nhats.org/); the National Center for Health Statistics (http://www.cdc.gov/nchs/index.htm) and the Center for Medicare and Medicaid Services (http://www.cms.gov/Research-Statistics-Data-and-Systems/Research-Statistics-Data-and-Systems.html).
Outside of mainstream healthcare settings, patient/disease registries represent powerful repositories of research data, and patient profiling that can be used for surveillance and for monitoring disease burden among sectors of the population. There are thousands of such registries, focused on different diseases including: the Global Alzheimer’s Association Interactive Network (http://www.gaain.org/ ); the National Program of Cancer Registries (http://www.cdc.gov/cancer/npcr/ ) and National Cardiovascular Data Registry (http://www.cdc.gov/cancer/npcr/ ). In addition, these resources are being used to connect patients with specialist physicians and with clinical trials that cover their distinctive medical needs.
Sources of data such as these summarized above are being used to support clinical assessment of the need and market opportunity for next generation drug development and approval. The NIH offers and online registry of scheduled and ongoing clinical trials ( https://clinicaltrials.gov/) within the US. An equivalent registry covers clinical trials in the EU ( https://www.clinicaltrialsregister.eu/ctr-search/search) and the WHO supports a similar compilation across more than 15 trial registries spanning different regions of the globe (http://apps.who.int/trialsearch/).
The goals of the registries listed here are to pull together data from different sources to better equip population health initiatives, allocate resources and ultimately improve individual patient care. Whether that means supporting access to the best treatment available resources, identifying the areas of greatest need, or connecting with other patients, these databases are becoming foundational for understanding the changing medical needs of our ever-growing population. And as drug developers are responding to these needs, these datasets are becoming valuable tools in supporting optimal therapeutic development, clinical trial design and approval for innovative medicine.
With a shift in focus to individual patients and personalized medicine approaches, we can anticipate even more groundbreaking developments in healthcare. Large datasets will lead to more efficient and safer clinical trials, faster drug development cycles, and ultimately, improved patient outcomes.
Nowhere will this be more profound than with the development of orphan drugs. Orphan drugs are medications designed to treat rare diseases, affecting a small percentage of the population. Historically, the development of these drugs faced numerous challenges, including limited patient data and high research and development costs. While individually orphan diseases may be rare, collectively, they impact millions of people worldwide. Due to the limited patient pool, traditional drug development approaches were often deemed economically unviable, resulting in a dearth of treatment options for those afflicted. Big data is changing this narrative by providing novel avenues to identify potential therapeutic targets and streamline the drug development process. It is also enabling researchers to explore existing drug databases to identify compounds with potential therapeutic effects for orphan diseases.
Examples of such successes include the development of Ivacaftor for cystic fibrosis (CF) a genetic disease caused by mutations in the CFTR gene and an incidence of 1 in 4000 in the U.S. where large ethical variations are observed (Sullivan B.P., Freedman S.D. 2009). Vertex, the company who developed this drug used big data analytics to identify specific mutations within the gene encoding the CFTR protein, and then screened thousands of small molecules for their potential to correct the defective protein activity (Condren et. al. 2013). Since the approval of Ivacaftor, Vertex has developed additional drugs, including lumacaftor/ivacaftor (Orkambi) and tezacaftor/ivacaftor (Symdeko) that target different mutations with additional truly precise therapy solutions to patients with cystic fibrosis.
Similarly, Amicus Therapeutics utilized big data analytic modeling to develop a pharmaceutical chaperone to treat Pompe disease. Pompe disease, also known as acid maltase deficiency or glycogen storage disease type II, is a rare genetic disorder with an incidence in the U.S. of 1 in 28,000 and characterized by the accumulation of glycogen in cells, leading to muscle weakness and other symptoms. Amicus researchers used big data analytics to understand the underlying biology of Pompe disease, including the specific genetic mutations associated with the disorder and the impact of enzyme deficiency on cellular function. The company then developed ATB200, an enzyme replacement therapy (ERT), which is a recombinant form of human acid alpha-glucosidase (rhGAA) (Blair, 2023). ATB200 was designed to be administered intravenously to deliver the functional enzyme to affected tissues, facilitating the breakdown of accumulated glycogen. In combination with ATB200, the company developed AT2221, a pharmacological chaperone designed to enhance the stability and trafficking of the enzyme, increasing its activity within cells. Using this proprietary chaperone technology, the effectiveness of the enzyme replacement therapy was optimized and markedly improved its therapeutic impact. The development of therapies for Pompe disease by Amicus Therapeutics exemplifies the importance of big data in drug development for orphan diseases. Only using a comprehensive and collaborative, data-driven approach, was it possible to combine ERT with innovative pharmacological chaperone technology to develop a safe and effective combination therapy for this orphan disease (Lun et. al. 2019).
The concept of collectively analyzing healthcare data from a diverse range of sources is challenging at many levels, but with the rollout of advanced analytics, coupled with the promises of artificial intelligence, big data analytics continues to reshape the healthcare landscape. However, as we navigate this frontier, it is important to consider the ethical considerations around EMRs and patient information, as well as governance of how that data is used in order to ensure that the potential benefits of big data in clinical trials are realized responsibly and equitably.
The transition of drug development and clinical trials to big data represents a pivotal moment in the evolution of healthcare. By harnessing the power of vast and complex datasets, researchers can unlock new insights, accelerate the pace of discovery, and launch an era of more personalized and effective medical treatments.
